4.4.1. Method
Infrastructure
As the platform for the project was selected DigitalOcean (“Paperspace,” n.d.; “DigitalOcean,” n.d.). It offers preloaded machine learning frameworks. Therefore, the burden of preparing the machine learning environment from scratch was skipped. This wasn’t the case for other platforms that were evaluated during the project. In other cases, the dependencies must be either installed manually or require special docker images, which in our case almost meant learning how to build a complete machine-learning infrastructure from scratch. Explaining the complete experience and providing a deep comparison could be for another article.
Along with the pre-loaded infrastructure, the offer of NVIDIA GPUs (“NVIDIA GeForce Graphics Cards,” n.d.; Tsu 2022) provided the capability to change the GPU anytime without needing a complicated setup. Other platforms offered similar possibilities, but the provided GPU options were narrower, or the switch between the machines was not as straightforward as on the selected platform. Of course, local computers don’t offer a change of CPU or GPU on demand at all.
Datasets
The experimental evaluation employs a second dataset for comparative analysis – the SVG-Fonts dataset (Carlier et al. 2020). This widely adopted collection in machine learning research presents an intriguing contrast to LTTR/SET. While it boasts an impressive scale of approximately 14 million fonts, the experiment utilises a subset of 8,000 fonts – the same collection featured in the original DeepVecFont project. Where LTTR/SET offers a limited however meticulously curated set of shapes, the SVG-Fonts dataset presents an unrestricted diversity that, whilst expansive, lacks systematic quality curation. This juxtaposition of approaches – one precise and bounded, the other vast and varied – provides fertile ground for comparative analysis.
Training
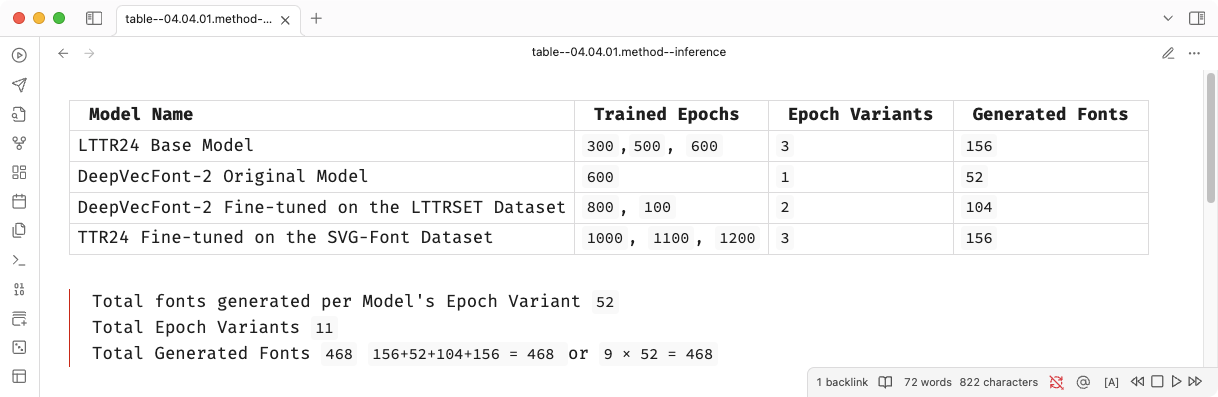
For the experiment three distinct models were produced. Every training session used the same batch size of 32 fonts per iteration. First, the model trained on the LTTR/SET is called the LTTR24 Base Model. It is trained for 300, 500, and 600 epochs. The next two models were fine-tuned 1 with different data sets from their pre-trained versions. The original DeepVecFont-2 (Wang et al. 2023) model trained for 600 epochs was fine-tuned 2 with LTTR/SET to 800 and 1000 epochs. Accordingly, the LTTR24 Base Model was fine-tuned with the SVG-Fonts Dataset to 1000, 1100 and 1200 epochs.
Inference
The inference task focused on font completion. It could be concluded as the most convenient ML task for application in the type design industry. The goal was to compare the models and their training strategies based on the capabilities to perform font completion. Therefore, the original DeepVecFont-2 (Wang et al. 2023) model was included in an evaluation as well.

The testing set comprised 13 fonts, each representing a different style and comprising only four characters. The font styles were created with the LTTR/INK technology (“LTTR/INK” 2017–2024). Therefore, they represent its specific aesthetics.
The reference characters could be set as random. However, for this project, a specific set of characters was selected. Those characters were the best candidates for representing the distinctive font style characteristics.
ax-height, bowl, arc, joints, junctions, serifshascender, arcs, junctionsocircular shape, best for stroke contrast evaluationydescender, diagonals
When generating the missing fonts, the models were tasked with
generating 20, 30, 50, and
100 trial samples before selecting the best set to complete
the full alphabet. The objective was to assess how much generation
effort was required for each model to achieve an optimal result. The sum
of 4 trials for each reference style, resulted in
a minimum of 52 generated fonts per model.
Since the number of reference fonts is 13, every time a model inference is run, it generates 13 fonts. The total number of generated fonts is then determined by the number of the model’s epoch variants multiplied by the number of generated fonts per model.
Note that fine-tuning doesn’t target specific layers or features of the pre-trained model to simplify the technical implementation of the demonstration.↩︎
Note that fine-tuning doesn’t target specific layers or features of the pre-trained model to simplify the technical implementation of the demonstration.↩︎
