3.3.1. Brief Journey Into Numerical Representation
In the machine learning pipeline, data encoding serves as the crucial bridge between domain-specific data formats and the numerical representations required by learning algorithms. Consider the initial state of domain data, nestled comfortably in its native habitat.
The state of data exists in various domain-specific formats, each carrying its own conventions and structural peculiarities. The following table illustrates common domains and their corresponding native formats:
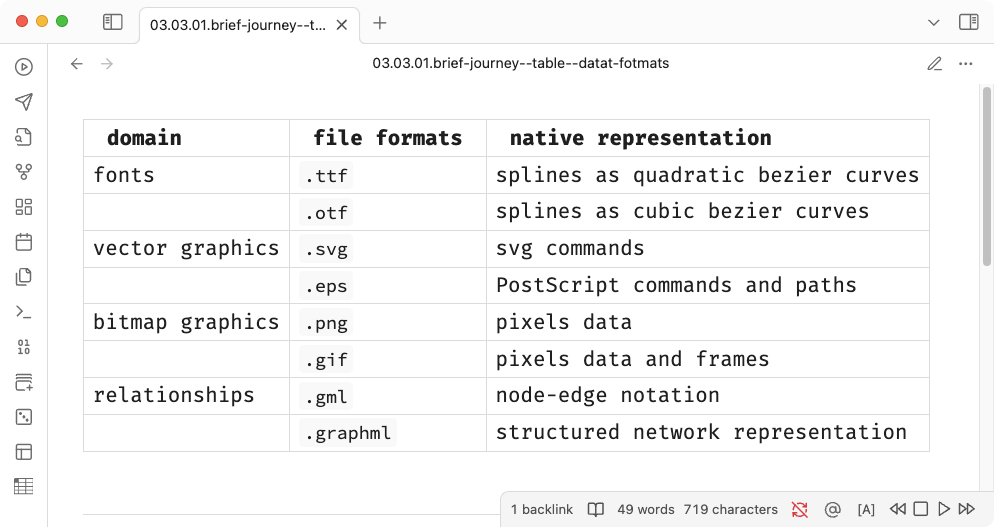
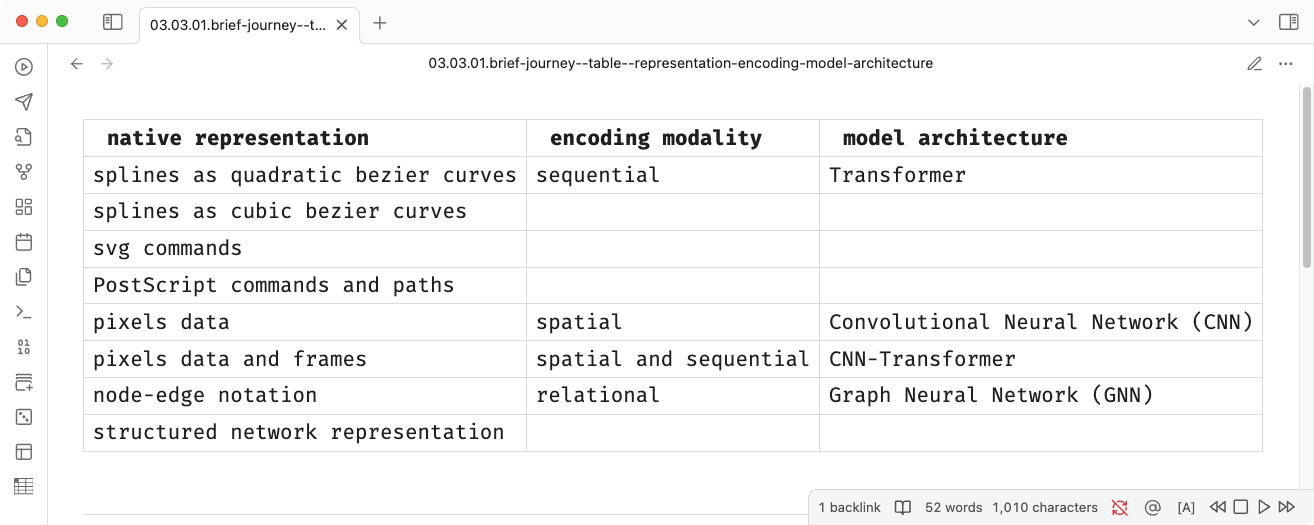
This native representation undergoes an encoding process to produce a
numerical representation suitable for machine learning algorithms,
typically stored in .npy or .npz files. For
deep learning algorithms, these numerical representations manifest as
tensors with specific encoding modalities:
Once encoded, this numerical data serves as the foundation for model training. Based on the encoding modality, specific neural network architectures are chosen to recognise patterns and abstractions within the data – not unlike how a type designer learns to spot the subtle differences between Helvetica and Arial.
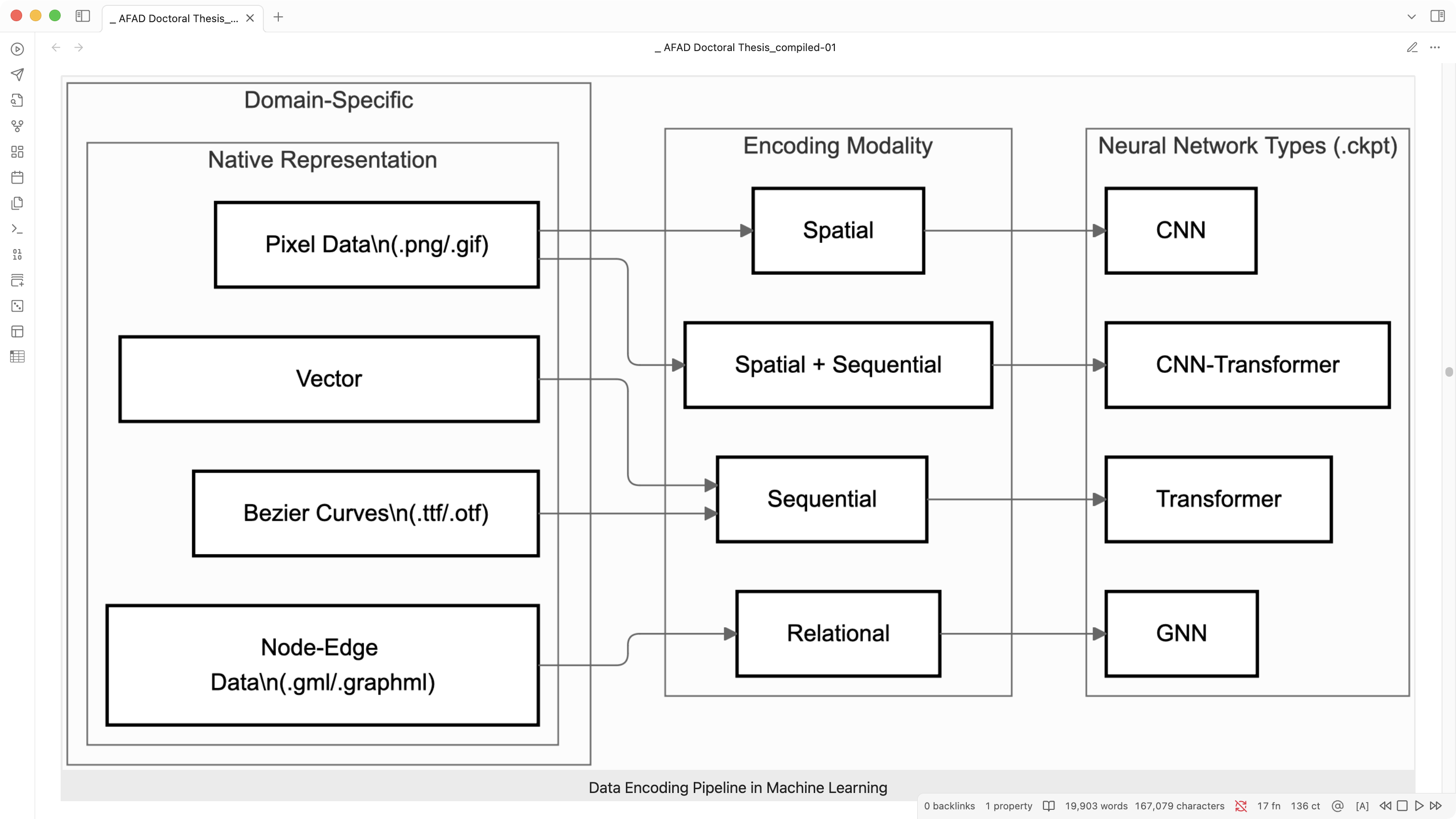
The above-mentioned content presents a deliberately simplified overview of the machine learning pipeline, whilst the actual implementation harbours considerably more technical nuance and architectural sophistication.
