3.2.3. Observations
There are hundreds of thousands of fonts in databases, commercial and open-sourced (Google, n.d.; Fonts, n.d.; Inc., n.d.). Those databases seem to be large enough to train vector font generation. Even gathering colossal libraries of font data is apparently not such a problem (Lopes et al. 2019).
Contrary to belief, the dataset size doesn’t require an enormous number of examples to be effective. In fact, previous studies contained as few as 46 font examples (Campbell and Kautz 2014). When developing the font dataset, it is important to set a foundation that can be extended easily.
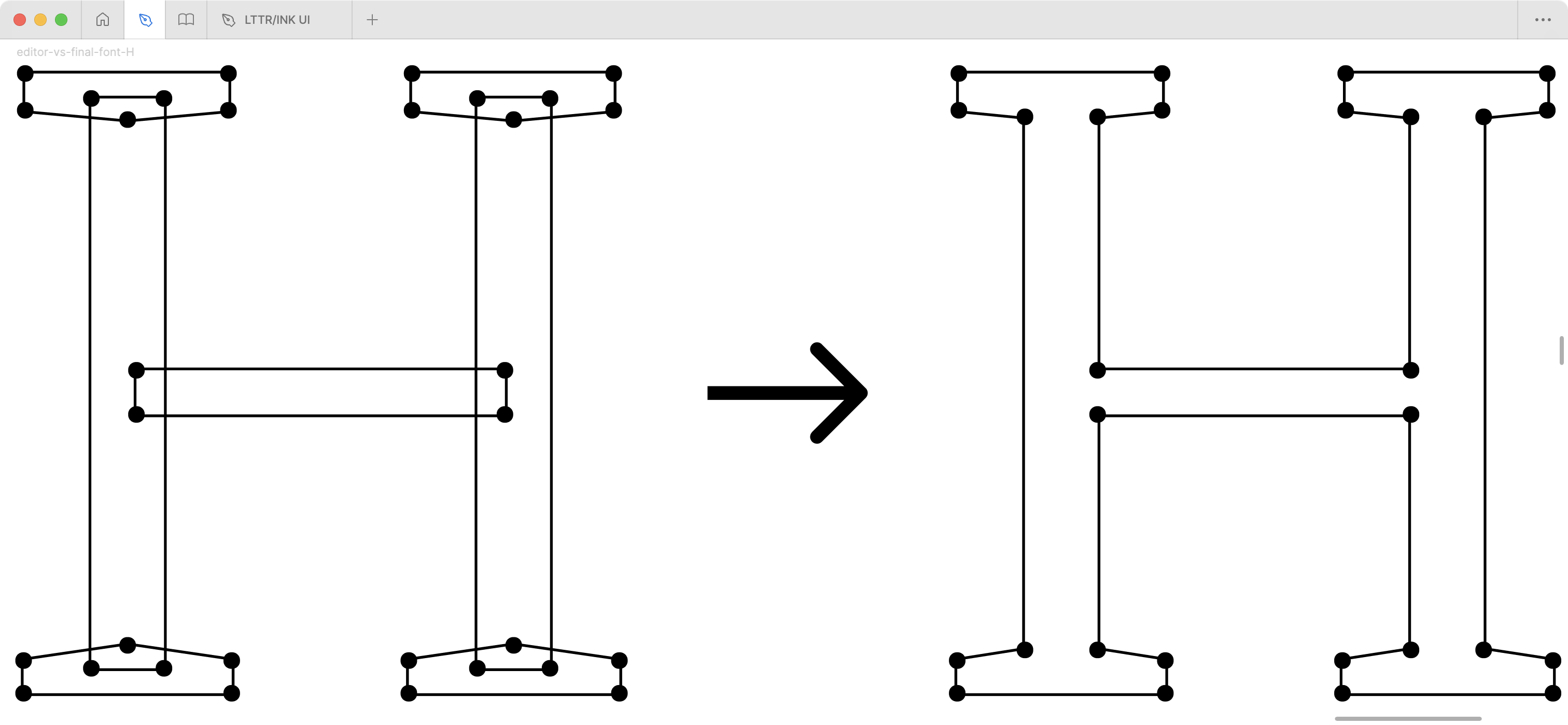
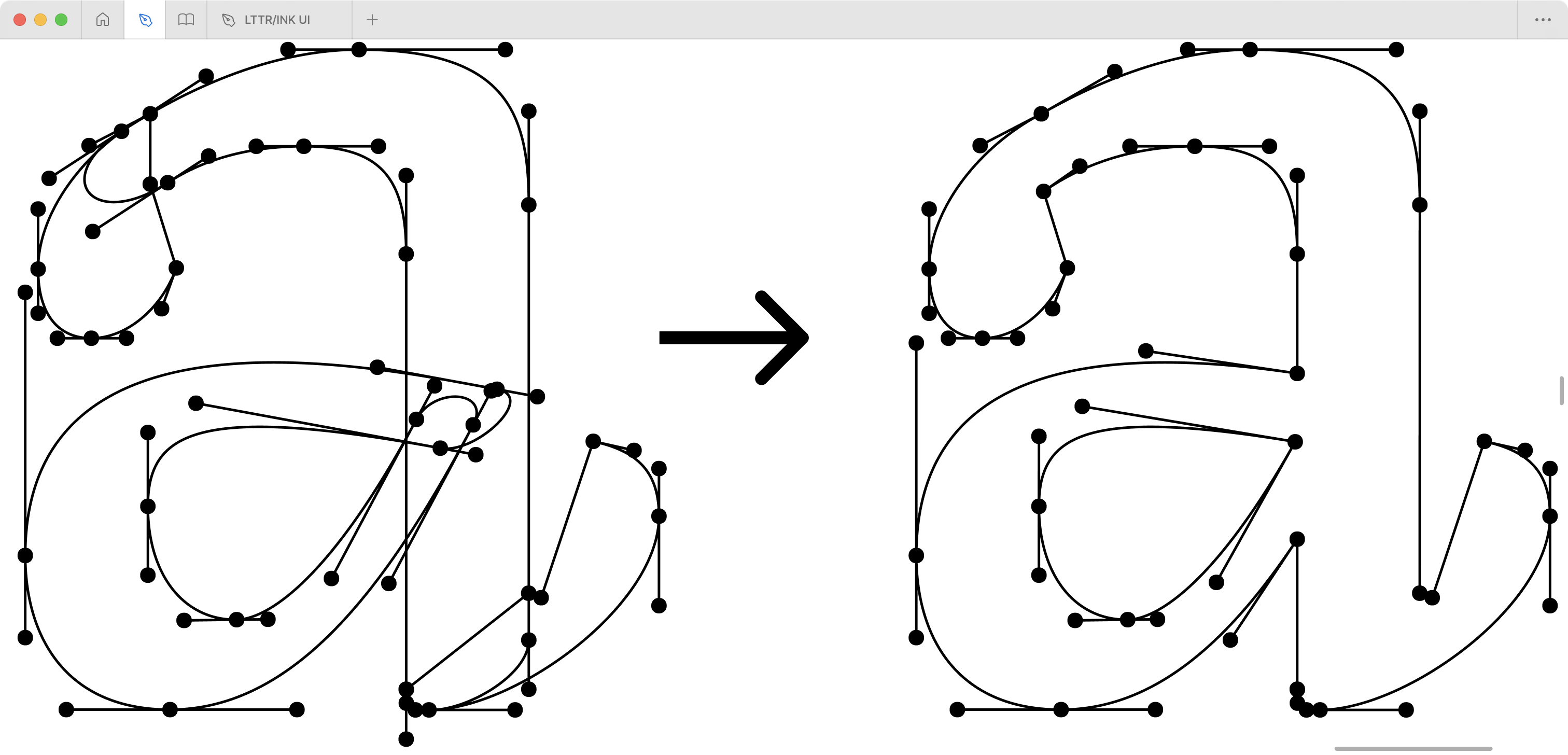
A curious observation emerges regarding vector representation: none
of the examined datasets utilises original designer drawings from source
formats such as .ufo, .sfd or
.glyphs. These working files, rather like an artist’s
sketchbook, contain valuable geometric relationships absent from the
final .otf or .ttf font files. The letter
H serves as an illuminating example – type designers rarely
conceive it as a single shape, instead constructing it from three
distinct components: two vertical stems joined by one horizontal stem.
When serifs enter this geometric dance, they manifest as four additional
independent shapes. This decomposition into constituent elements reveals
crucial insights into the designer’s creative process – insights that
vanish like the Cheshire Cat’s grin in the transition to the final font
files.
