2.3. Compilation: The Database of AI font Generation Projects
The culmination of the Initial Research manifests as an extensive database encompassing bibliographic academic studies on AI Font Generation. This database functions as an indexed directory, categorising each paper and summarising its details according to observed topics. This systematic arrangement is reminiscent of a meticulously arranged gallery, where each artwork is positioned to highlight specific themes, thereby facilitating coherent exploration. Consequently, the database serves as a foundational resource for conducting surveys within designated areas of interest.
Discrepancies emerge as databases expand due to the continuously evolving taxonomy. Furthermore, the management of databases becomes more challenging with the increasing volume of data, resulting in some columns remaining empty.
To address these inconsistencies, ChatGPT (“ChatGPT,”
n.d.) was employed to assist in extracting content based on
predefined topics. The process involved refining term definitions and
mappings to optimise results. A streamlined three-step protocol of
prompts was established: 1.) introducing objective, definitions and
mappings; 2.) specifying the database format; and 3.) generating
corresponding row from each research paper. This final step was
iteratively applied across all projects. The resulting data was manually
integrated into the database with citation keys before being exported to
a .csv file that includes both citations and relevant
links.
This protocol presented two nontrivial weaknesses. Firstly, it necessitated extensive manual intervention for prompting, data input, and general oversight. Secondly, ChatGPT’s (“ChatGPT,” n.d.) tendency to fabricate information rather than precisely extract facts proved problematic – much like a well-meaning but overzealous research assistant who, rather than meticulously transcribing archival documents, occasionally embellishes them with creative interpretations. This imprecision resulted in an additional burden of fact-checking and correction.
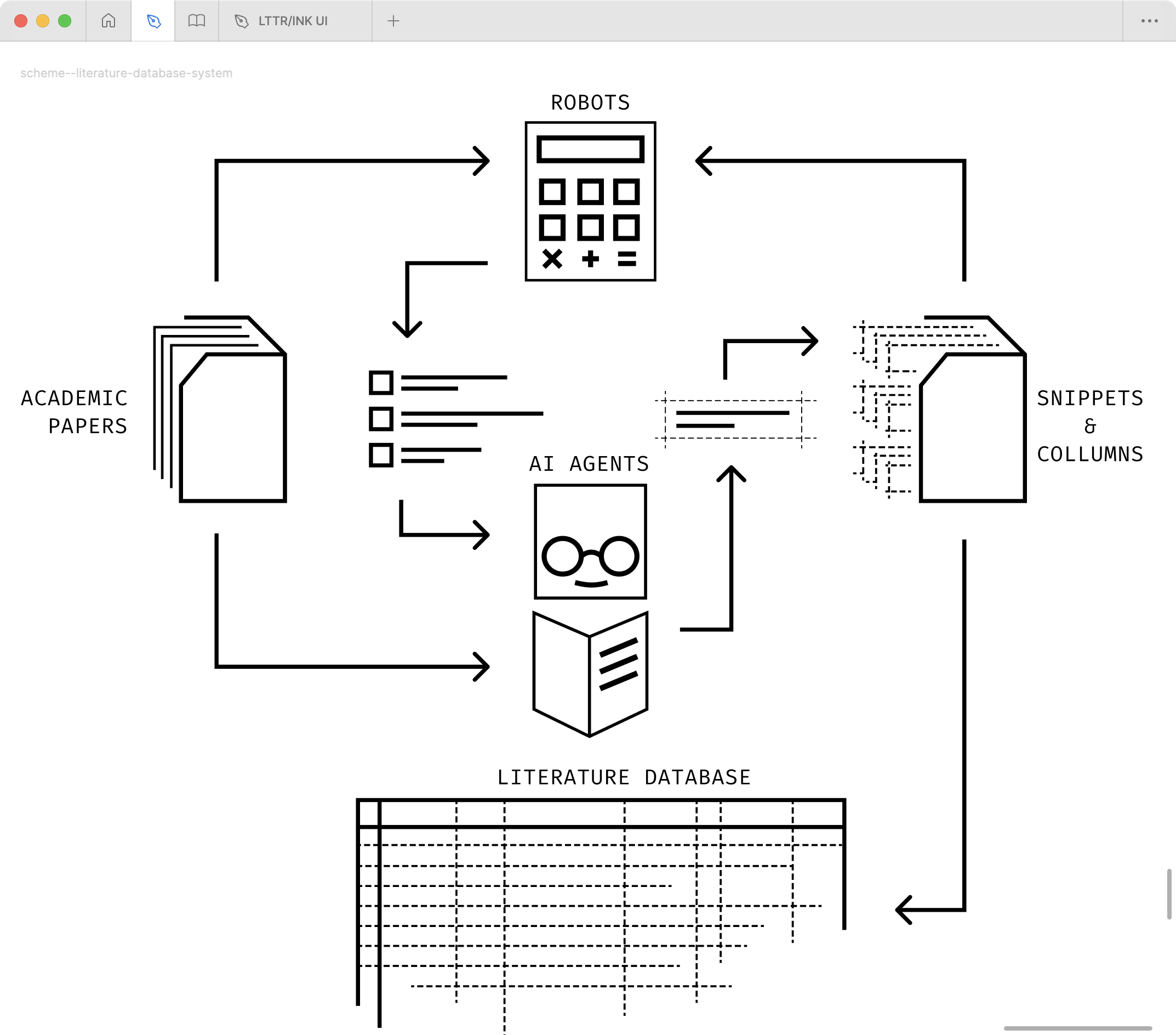
Later, in the refactoring phase, a sophisticated system was developed that leverages autonomous AI agents – particularly the Cursor IDE agent (INC, n.d.) – that acted as two autonomous researchers: 1) snippet extractor and 2) cell summariser. The system’s architecture comprises two distinct operational layers: automated robotic components and intelligent AI agents.
The robotic layer encompasses three specialised components:
- A snippet verification robot that systematically examines text extractions according to predefined topics
- A database integrity robot that monitors completion status and mapping alignment
- An integration robot that automatically appends validated content into the database
The AI agent layer operates through two agent definitions:
- The extraction of relevant snippets from academic papers with precise topic references
- The compilation of structured database rows from the extracted snippets
The system’s capabilities were further enhanced through the integration of Claude (PBC, n.d.-b), developed by Anthropic (PBC, n.d.-a), which offers superior precision and reliability in natural language processing tasks compared to former ChatGPT (“ChatGPT,” n.d.).
The efficiency gains achieved through this automated system are comparable to the transformation of a manual assembly line into a modern automated factory - where previously laborious hand-crafted processes have been replaced by precise, tireless robotic systems that maintain consistent quality whilst operating at significantly higher throughput rates.